北京本轮那一场疫情的感染率或许已经超过了80%,石耀林院士所带领的团队运用数学模型揭示出了这个关键数字背后所蕴含的依据,借助简化病毒传播机制的方式,利用有限的数据去反推参数,他们描绘出了疫情发展的曲线,并且针对后续趋势做出了判断,而这有可能是近期最值得人们予以关注的专业分析当中的一个。
简化模型抓住关键参数
石耀林院士队伍于构建模型之际,最先针对繁杂状况加以简化,鉴于奥密克戎具备潜伏期短暂、感染进程快速之特征,该模型当下暂且搁置了潜伏期、传染期等变量,仅仅着重于一个关键数值,即感染率R0,亦即是一名病患在单位时间之内会致使多少人被感染。
在疫情刚开始的时候,数据处于匮乏状态之际,这样的做法显得特别有必要,通过精准抓住关键矛盾所在,模型能够迅速搭建起基础框架的模样模样,进而为接下来的参数校准以及政策评估提供根本基础,这情形如同医生先是测量体温的数值,随后再安排进行详细的检查那般。
分段拟合校准传染率
对于北京疫情发展,模型划分出了不同时段,在这些时段里分别去尝试不同的Rt值。第一段时,Rt被设为1.44。这主要是依据11月下旬公开以及半公开的资料。而在开放后的第二时段,是通过调整Rt以此来拟合实际调查的数据。
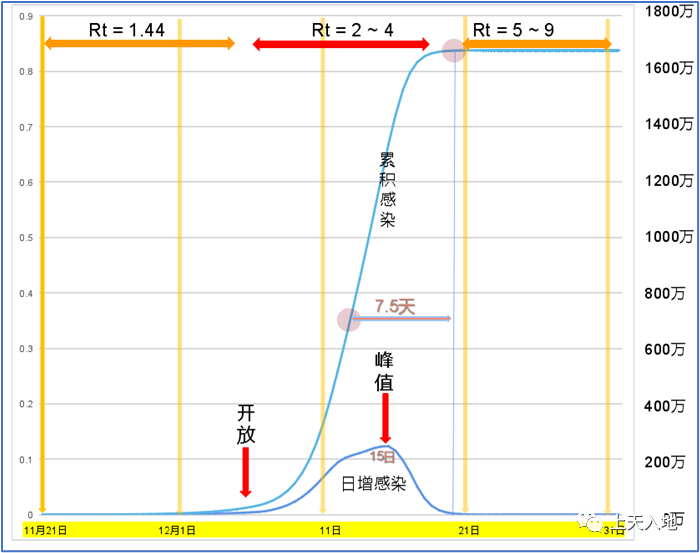
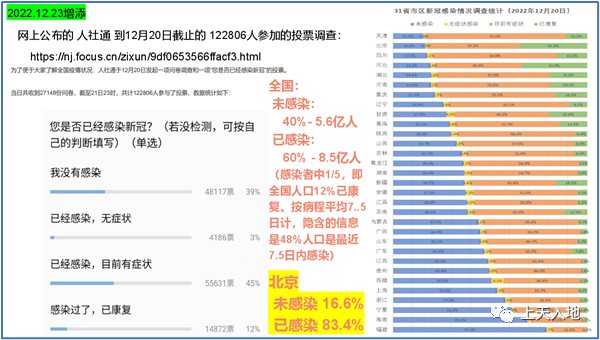
以下这些约束条件涵盖:12月20日的时候,累积感染者达成了83.4%,同日存在35%的感染者已经康复,按照平均病程7.5天进行反推计算,在12月12日的时候,累积感染应当是35%,百度健康问诊指数于12月15日达到峰值,经过多重校准之后,模型寻觅到了跟现实最为匹配的参数组合。
数据局限与校正方法
任意一种模型均会遭遇数据质量方面的挑战,这次采样主要涵盖拥有智能手机而且留意搜寻信息的活跃人群,老年人以及少儿的代表性欠缺之处。不过团队通过分析得出这样的看法,少儿大多和活动人群居住在一起,感染的比例应该是相近的,60岁以上的老年人占据人口的18%,或许是需要进行校正的。
假设,老人感染的比率,仅仅是活动人员的三分之二,那么,校正之后,北京没有感染的人口,大约是22%,已经被感染的则是78%。石耀林进行提醒,感染数字5%的差异,就对应着100万人口的浮动,对于基于不确切数据的模拟来说,应该主要去看趋势,而不是死抠数字。
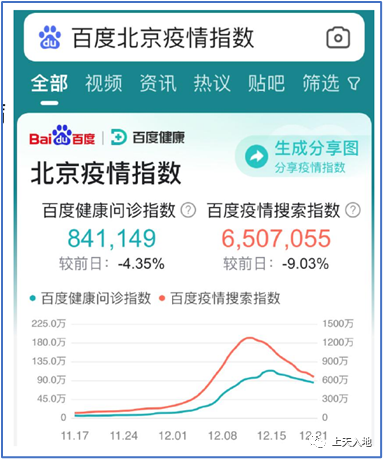
问诊指数验证曲线形态
在此次模拟里,百度健康问诊指数发挥了关键验证作用,因为患病者更有上网搜索问诊的可能性,所以该指数于12月15日达到峰值,模型把这一日期当作日新增感染者达峰的重要约束条件。
模拟的,日增感染者曲线迅速上升的那段,跟问诊指数展现出类似的背拱形态。鉴于症状持续大概一周,问诊指数曲线相较于模拟的新增曲线,理应会有七天左右的滞后,这样的逻辑有待后续数据进一步去验证。
高感染率意味着什么
预测模型显示,北京的第一波疫情还没结束,然而已经感染的人数或许已达总人口的83%,或比83%稍微少些。就算往后存在人员流动的情况,疫情依旧有可能出现小幅度的起伏,不过大概率不会出现单日新增人数超过10万的巨大峰值。
石耀林作出解释,2000万人口当中,已经有大约1600万人感染过,此前单日新增上百万人次的峰值都已经经历过。在这种由于高感染率而形成的群体免疫屏障面前,病毒再怎么闹腾也难以掀起大的波浪来。
陡降曲线与后续免疫
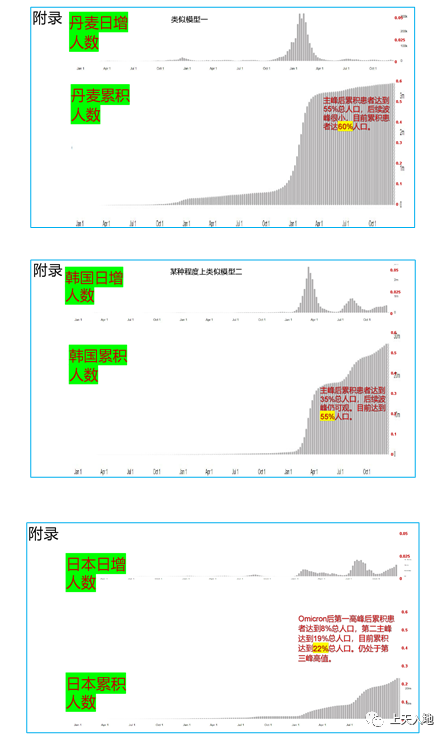
模型呈现出这样的情况,往后疫情下降的速度将会特别快,这和累积感染人数的基数存在直接关联,附录当中的国际对比给出了相应的佐证,日本累计感染仅仅只有22%,其曲线呈现出陡升缓降、多次出现波动的态势,丹麦第一峰达到了55%,曲线呈现出陡升陡降的情况,北京倘若达到80%,下降曲线会比丹麦的更加陡峭。
对于北京市民在最近这段时间内所做出的承担以及带来的牺牲而言,其最终换来的结果是在新年前后实现了第一波疫情的结束,并且由此获得了具备更强抵抗外界传入能力的群体免疫能力。从数据所呈现出来的趋势方面来看,这样的一个新年的确是值得人们去期盼的。
据石耀林院士所构建的模型来看,北京在本轮期间的感染率大概有可能或许已经达到了80%左右这个程度,你身处的城市或者所在的社区当下状况究竟是怎样的呢,欢迎于评论区之中分享你所观察到的处于一线的实际情况,同时也请将这份基于相关数据的具备专业性的分析转发给那些对疫情走向态势予以关心的朋友们。